
Tak jak już wcześniej wspomniałam uczę się korzystając z programu Microsoft Professional Program Certificate in Data Science. Jak to wygląda w praktyce?
Pierwszy kurs
Pierwszy kurs pt Data Science Orientation zawiera trochę informacji i wprowadzenia na temat tego co się będzie działo w programie oraz jak sobie zaplanować cały kurs by jak najwięcej z niego skorzystać i móc zrobić certyfikat na jego zakończenie. Jest to o tyle ważne, że mamy dokładnie miesiąc na skończenie kursu jeśli już go zaczęliśmy. Jeśli nie zdążymy właściwie nic wielkiego się nie skończy, ale jeśli będziemy chcieli uzyskać certyfikat będziemy musieli przejść wszystkie testy, które pojawiają się na zakończenie poszczególnych modułów oraz test końcowy.
Data Scientists
W tym pierwszym kursie bardzo podobała mi się część w której są wywiady z ludźmi pracującymi jako Data Scientist, gdzie opowiadają trochę o swoje pracy, tym czego od nich wymaga i co w niej lubią. Jedna z osób powiedziała coś takiego, że fascynuje ją iż nigdy nie wie czego dowie się analizując jakieś dane. Jest to zawsze niespodzianka i wielka zagadka. Myślę, że podzielam ten pogląd. Zawsze, gdy patrzę na jakieś analizy, dema i widzę jak różne informacje pojawiają się na koniec jest jest to dla mnie zawsze zaskakujące.
Excel Power
Poznałam również Excela od innej strony. Do tej pory kojarzył mi się z nudnym narzędziem. Tymczasem w trakcie tego pierwszego kursu miałam okazję nauczyć się analizować dane za jego pomocą korzystając z takich funkcji jak:
- Formatowanie warunkowe (Conditional Formatting), które pozwala na formatowanie komórek odpowiednio do zbioru danych w danej kolumnie. W ten sposób można na przykład pokolorować te komórki, gdzie znajdują się dane z Top 10 lub Top 10%, podobnie – Bottom 10 lub Bottom 10% aby móc jednym spojrzeniem zauważyć które komórki zawierają dane wartości. Można również automatycznie wyróżnić wartość największą lub najmniejszą.
- Slicer – jest to pewne rozszerzenie filtrów, które możemy mieć na poszczególnych kolumnach. Jednak różni się tym, iż w jednym możemy mieć dane tylko do jednej kolumny z wartościami filtru dla niej właśnie. Dzięki temu możemy filtrować dużo szybciej.
- Oprócz tego dużo różnych wykresów. W szczególności ważny jest histogram oraz wykres punktowy.
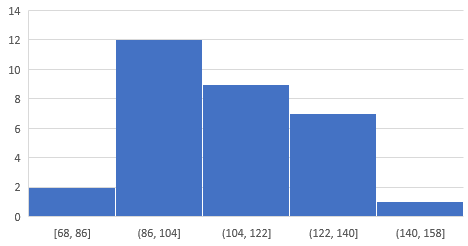
Histogram pozwala nam na zilustrowanie jak dane w zbiorze się rozkładają. Przykład z mojej nauki:
Widać na nim, że danych z zakresu 68 – 86 jest w moim zbiorze równo 2, danych z zakresu 86 – 104 jest 12, 102 – 122 jest 9 itd.![Histogram]()
Histogramy są tutaj o tyle ważne, że pozwalają wykryć nieprawidłowości w danych – jeśli na przykład któregoś “prostokąta” brakuje. Te zakresy oraz ilość prostokątów ustalamy sobie dowolnie zależnie od naszych potrzeb.
Z kolei wykres punktowy może nam pomóc w poszukiwaniu korelacji między dwoma wartościami. W ćwiczeniach z kursu szukałam korelacji pomiędzy sprzedażą napojów a ilością rozdanych ulotek i tak wyglądał mój wykres:
Akurat ten wykres potwierdza korelację pomiędzy tymi dwoma rzeczami, ponieważ punkty układają się dość blisko siebie a przy tym idą od lewego dolnego punktu do górnego prawego. Mówi się również, że w tym przypadku korelacja jest pozytywna – wzrostowa. Gdyby dane układały się od lewej górnej części do prawej dolnej – byłaby to korelacja negatywna.![Wykres punktowy]()
- Ciekawym typem wykresy jest też taki, którego nigdy wcześniej nie widziałam – czyli: wykres pudełkowy (Box and Whisker). Jest to wykres, który wygląda na przykład tak:
Co tutaj widzimy?![]()
Ilość sprzedanych napojów cytrynowych mieści się w zakresie od pomiędzy 60 a 80 i między 160 a 180 – bliżej 180. Podobnie w przypadku pomarańczowych – zaczyna się nieco ponad 40 i kończy pomiędzy 120 a 140. Zatem wartości maksymalne i minimalne zaznaczone są poprzez poziome kreski zwane również wąsami.
A co z prostokątami? Jakbyśmy spojrzeli na to pod kątem 90 stopni to można zauważyć, że zajmują one pewien zakres wartości – lewy bok znajduje się około 100 i wyznaczony jest przez pierwszy kwartyl a prawy bok wyznaczany jest przez trzeci kwartyl. Pierwszy kwartyl to zbiór danych, które położone są poniżej 25%. Natomiast trzeci to dane znajdujące się powyżej 75%. Przykładowe dane na temat sprzedaży jakie miałam do dyspozycji na temat napojów cytrynowych to: 97, 98, 110, 134, 159, 103, 143, 123, 134, 140, 162, 130, 109, 122, 98, 81, 115, 131, 122, 71, 83, 112, 120, 121, 156, 176, 104, 96, 100, 88, 76. Jeśli ktoś chciałby sobie to jakoś bardziej poanalizować, to może się przydać:) - Używane są również wykresy słupkowe, liniowe i dużo rzadziej – kołowe.



Statystyka
Pojawiły się też pojęcia ze statystyki – zarówno te, które pamiętam ze studiów jak i takie o których słyszałam pierwszy raz albo o nich zapomniałam;)
- Średnia – termin, którego chyba nie trzeba wyjaśniać:)
- Mediana – wartość środkowa poniżej i powyżej której znajduje się dokładnie taka sama liczba danych.
- Dominanta – wartość najczęściej występująca w danym zbiorze
- Rozstęp/zakres – różnica między największą i najmniejszą wartością w zbiorze
- Wariancja – informacja na temat zróżnicowania danych w zbiorze
- Odchylenie standardowe – informacja na temat jak bardzo dane są różne od średniej w danym zbiorze
- Błąd standardowy – odchylenie standardowe średnich z prób
- Kurtoza – informacja na temat tego na ile dane są zbliżone do średniej
- Współczynnik skośności – pomaga określić czy dane są równo rozłożone po obu stronach średniej czy może któreś dane leżą dalej od średniej
- T-Test – pozwala nam porównać ze sobą dwa zbiory danych
Uff, trochę tego jest – wszystkie trudniejsze pojęcia podlinkowałam do Wikipedii. Notka urosła długa, więc Python zostanie na następną okazję. Natomiast jeszcze muszę wspomnieć, że oczywiście danych do ćwiczeń z kursu nie musiałam preparować sama – więc nie rozdawałam ulotek, nie sprzedawałam napojów ani nic takiego:) Dane były do ściągnięcia w ramach kursu:) Czy pochodzą z życia? Kto to wie. Ale na potrzeby kursu sprawdziły się całkiem nieźle.

